Dados
Peguei os dados das pesquisas registradas usando no site pooling data http://www.pollingdata.com.br. Mas quem quiser, pode baixar o arquivo csv aqui.
library(tidyverse)
library(lubridate)
### Using this because I am lazy to upgrade my linux
# INLA:::inla.dynload.workaround()
dados <- read_csv2(file = "files/PollingData - 2018-T2-Brasil-BR-President.csv")
dados1 <- dados %>% gather(Candidato, Prop,-Data,-Instituto, -link, -Entrevistas) %>%
mutate( Prop = Prop / 100)
dados2 <- mutate(dados, Total = `Bolsonaro (PSL)` + `Fernando Haddad (PT)`,
Bolsonaro = `Bolsonaro (PSL)` / Total,
Haddad = `Fernando Haddad (PT)` / Total ) %>%
select( Data, Bolsonaro, Haddad, Entrevistas, Instituto) %>%
gather(Candidato, Prop,-Data, -Entrevistas, -Instituto)Todos os votos e pesquisas
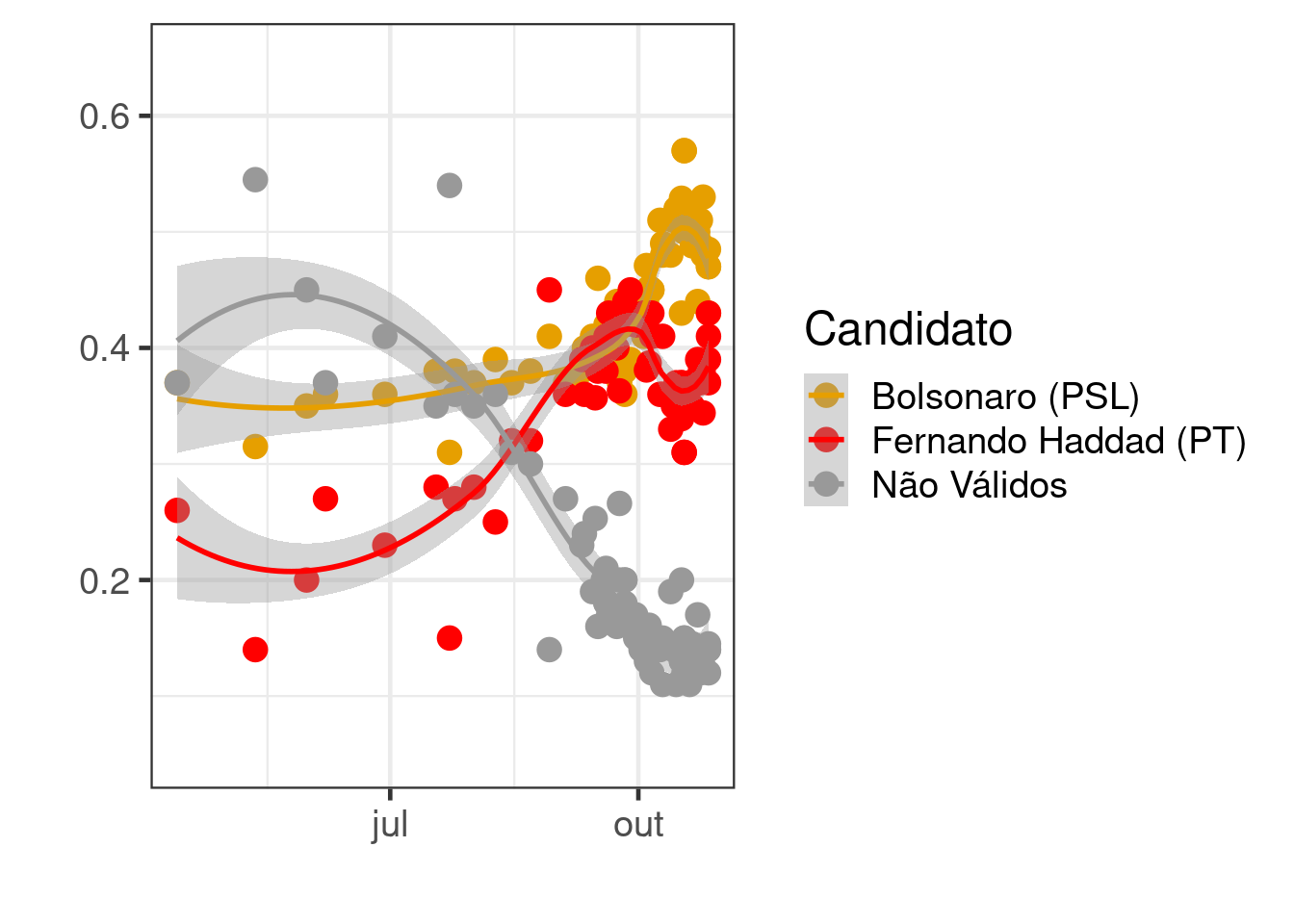
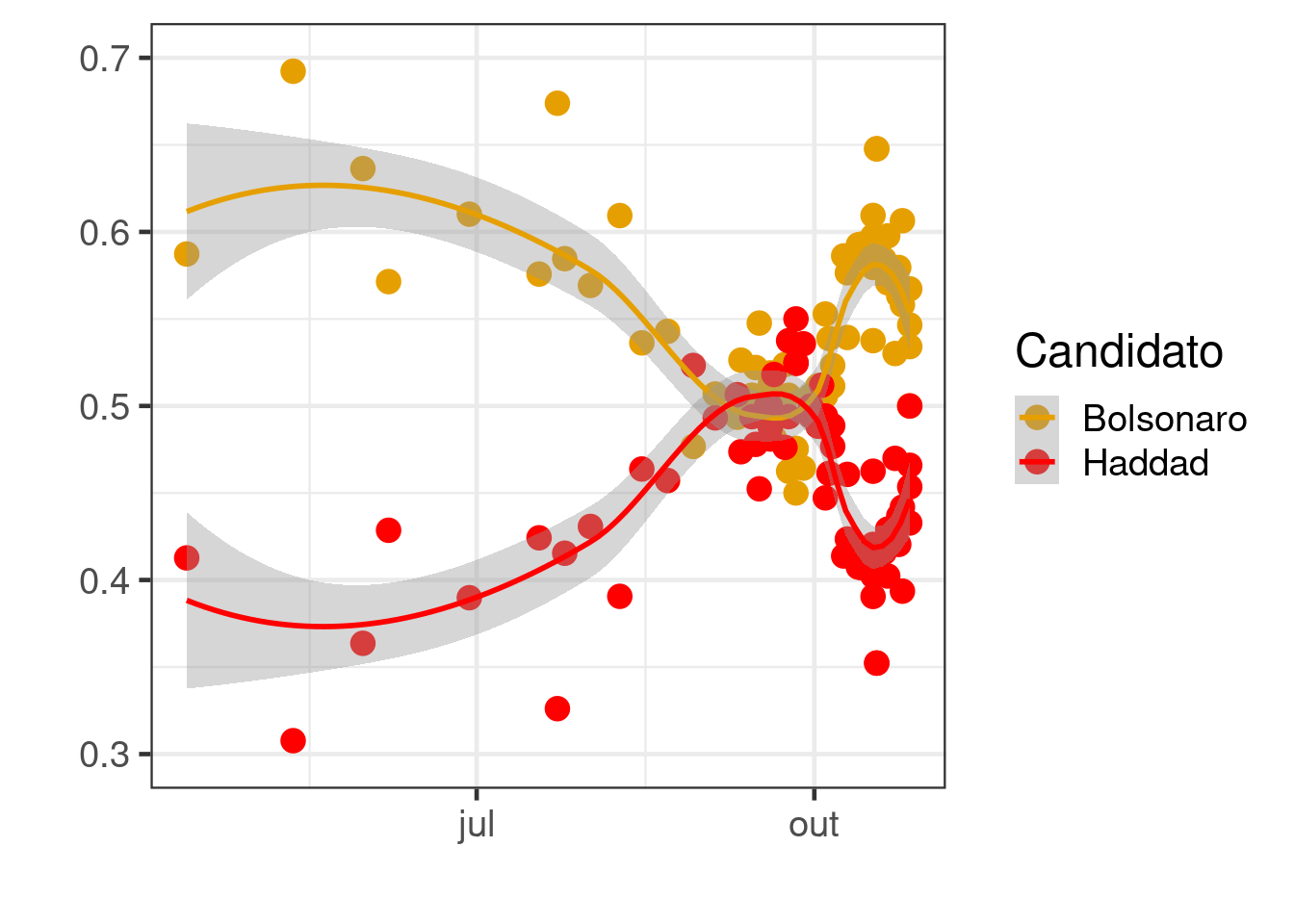
Considerando apenas as do segundo turno
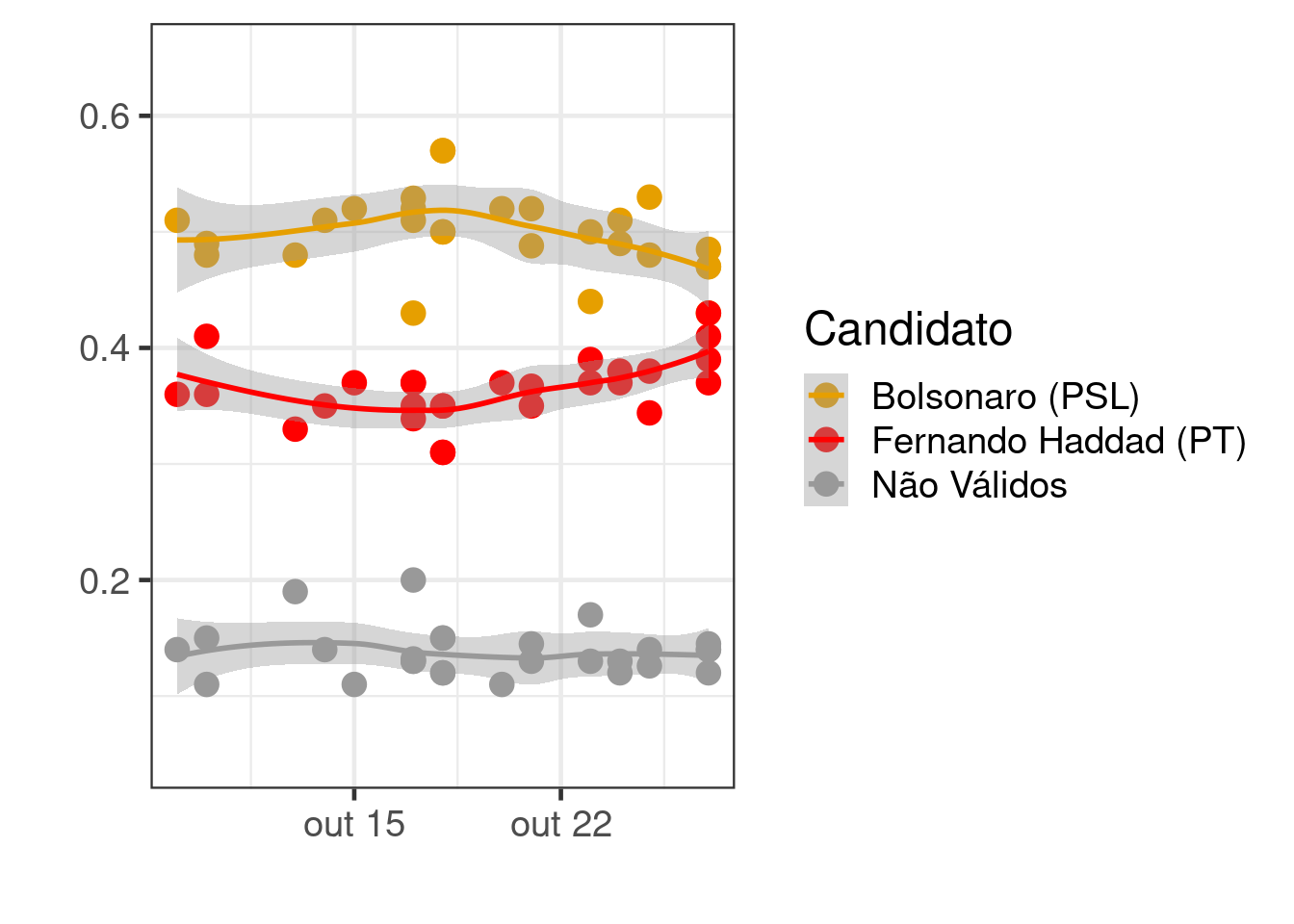
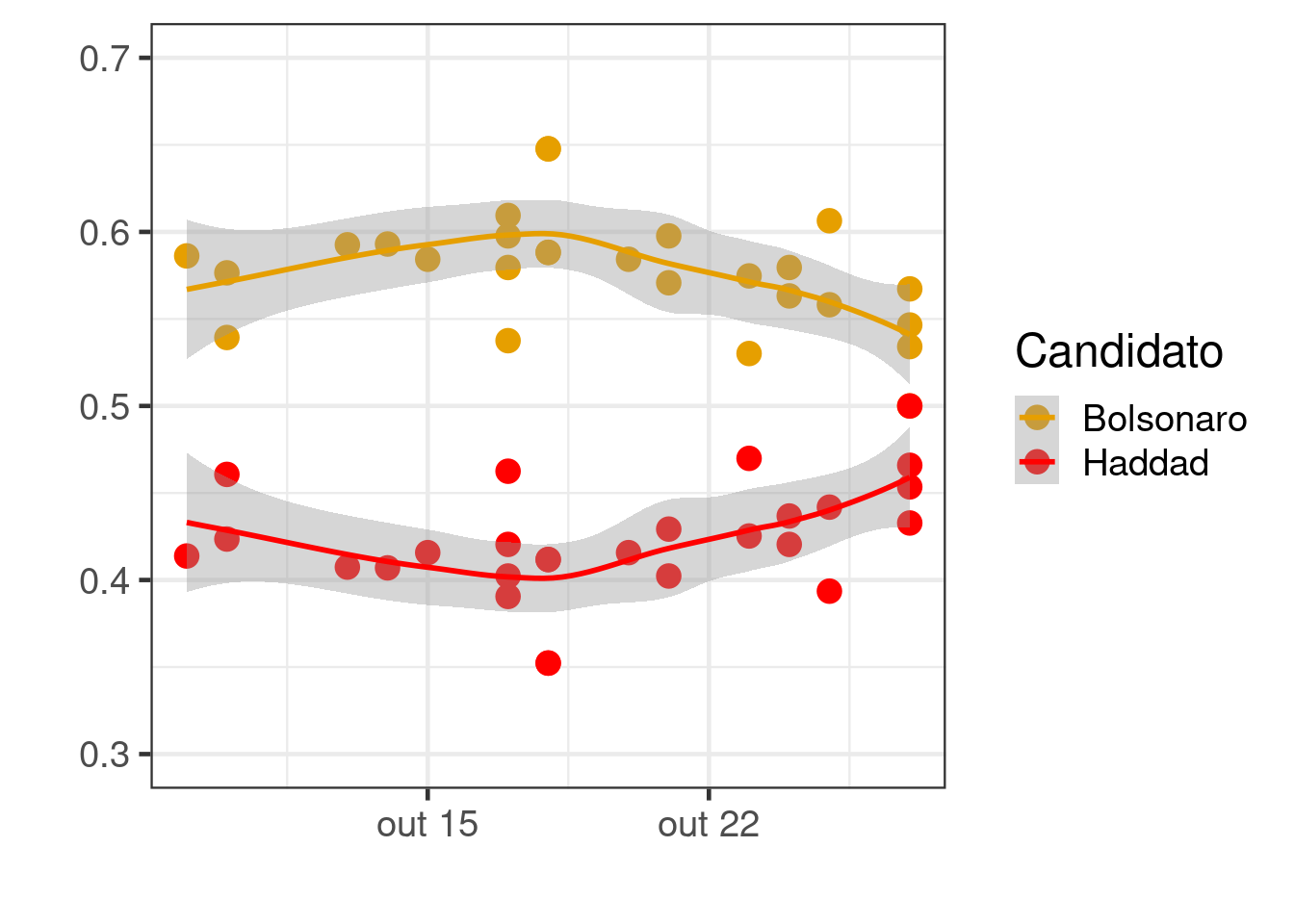
Modelando usando uma verossimilhança Beta e efeito aleatório dinâmico
\[Y_t \sim Beta(\mu_t, \phi), \quad t=1,2,\ldots \] onde \(t=1\) é o dia da eleição (não considerei o resultado da eleição do primeiro turno), a função de ligação é dada por \[logit(\mu_t) = \alpha + \beta_t\] onde \(\alpha\) é um efeito fixo, e \(\beta_t\) segue um passeio aleatório de ordem 2.
library(INLA)## Warning: package 'INLA' was built under R version 4.3.2# Somente segundo turno, votos válidos para Haddad e adicionado a data da eleicao
seq_2turno <- seq.Date(from = ymd("2018-10-07"), to = ymd("2018-10-28"), by=1)
dadosM <- filter(dados2, Data > "2018-10-07", Candidato == "Haddad") %>%
bind_rows(tibble(Data = seq_2turno, Candidato = "Haddad", Prop = NA)) %>%
mutate( Days = as.numeric( Data - min(Data) ) + 1,
Peso = round(Entrevistas / min(Entrevistas, na.rm = T))) %>%
replace_na(list(Peso = 1))
model <- Prop ~ 1 + f(Days, model = "rw2")
r <- inla(model, data = dadosM, family = "beta", control.predictor = list( compute = T, link = T))
Prediction <- as_tibble(
r$summary.fitted.values[(nrow(dadosM)-length(seq_2turno)+1):nrow(dadosM),]) %>% bind_cols(Data = seq.Date(from = ymd("2018-10-07"), to = ymd("2018-10-28"), by=1))
p1 <- ggplot(filter(dados2, Data > "2018-10-07"), aes(x = Data, y = Prop, color = Candidato)) + geom_point(size = 4) + theme_bw(base_size = 18) + xlab("") + ylab("") + scale_color_manual(values=c("#E69F00", "red")) + ylim(c(0.3,.7))
p1 + geom_line(data = Prediction, mapping = aes(x = Data, y = mode), color = "red") +
geom_ribbon(data = Prediction, mapping = aes(x = Data, y = mode, ymin = `0.025quant`, ymax = `0.975quant`), color = "red", fill = "red", alpha = 0.2) +
geom_line(data = Prediction, mapping = aes(x = Data, y = 1-mode), color = "#E69F00") +
geom_ribbon(data = Prediction, mapping = aes(x = Data, y = 1-mode, ymax = 1-`0.025quant`, ymin = 1-`0.975quant`), color = "#E69F00", fill = "#E69F00", alpha = 0.2)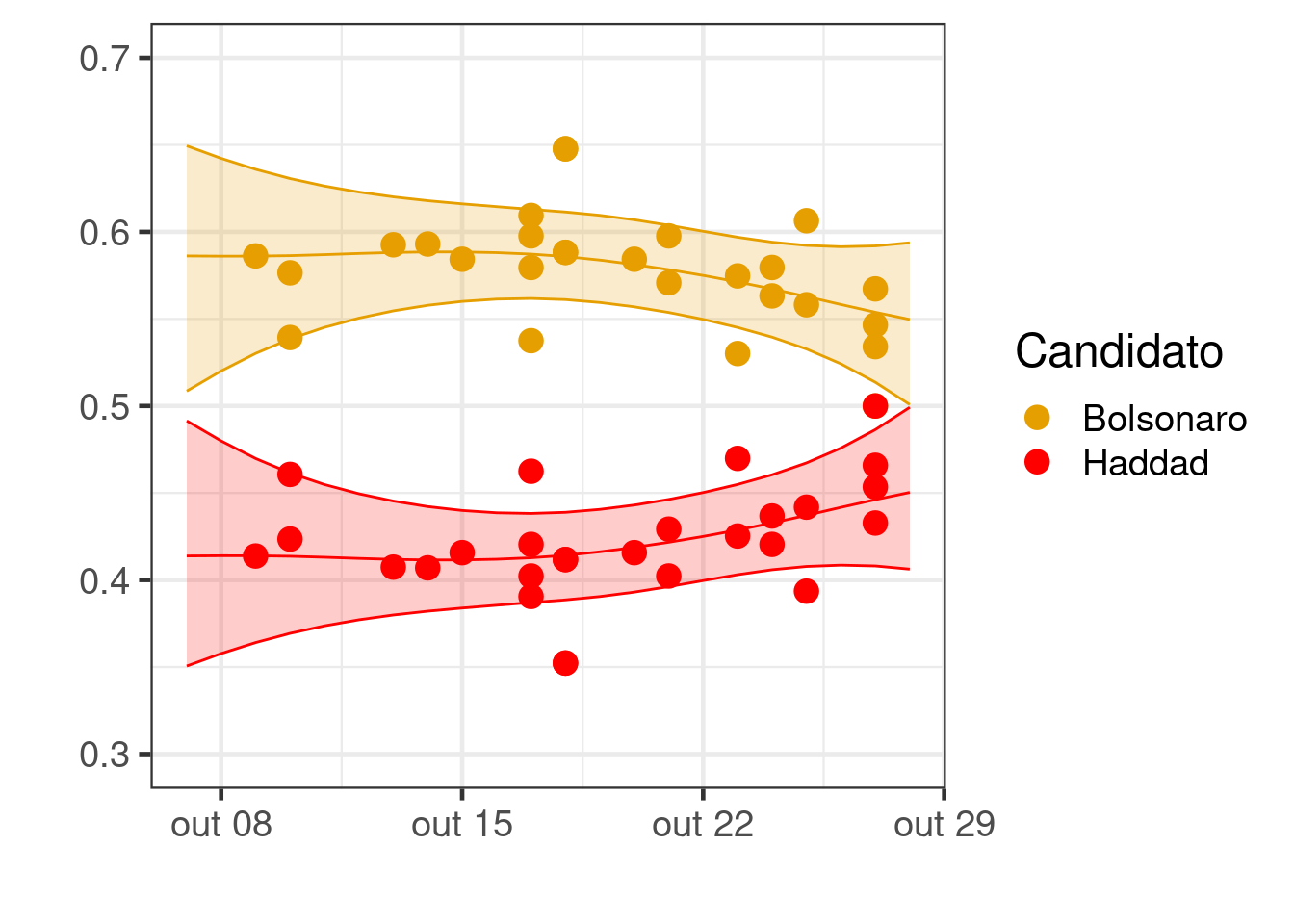
Estimativas de votos válidos do Haddad
tail(Prediction)## # A tibble: 6 × 7
## mean sd `0.025quant` `0.5quant` `0.975quant` mode Data
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <date>
## 1 0.429 0.0131 0.403 0.429 0.455 0.429 2018-10-23
## 2 0.433 0.0138 0.406 0.433 0.460 0.433 2018-10-24
## 3 0.437 0.0151 0.408 0.437 0.467 0.437 2018-10-25
## 4 0.442 0.0171 0.409 0.442 0.476 0.442 2018-10-26
## 5 0.447 0.0199 0.408 0.447 0.486 0.446 2018-10-27
## 6 0.451 0.0235 0.406 0.451 0.499 0.450 2018-10-28Note que a última linha é o dia da eleição.